Stable Diffusion is a machine learning model that can generate images from natural language descriptions. Because it’s open source, it’s also easy to run it locally, which makes it very convenient to experiment with in your own time. The simplest and best way of running Stable Diffusion is through the Automatic1111 repo, but there’s also a commandline friendly Dream Script Stable Diffusion fork, which comes with some convenience functions.
Setup
Install Anaconda
Download the Anaconda installer script from their website and install it. The download URL may change over time, so replace it.:
wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh
chmod +x Anaconda3-2022.05-Linux-x86_64.sh
# Install Anaconda without prompts
./Anaconda3-2022.05-Linux-x86_64.sh -bOnce installation is finished, initialise conda, but tell it not to activate each time the shell starts.
~/anaconda3/bin/conda config --set auto_activate_base false
~/anaconda3/bin/conda initGet the model file
The model file needed by Stable Diffusion is hosted on Hugging Face. You will need to register with any email address. Once registered, head to the latest model repository, which at the time of writing is stable-diffusion-v-1-4-original. Under the ‘files and versions’ tab, download the checkpoint file, sd-v1-4.ckpt.
Get the Dream Script Stable Diffusion repository
The Dream Script Stable Diffusion repo is a fork of Stable Diffusion, it comes with some convenience functions to accept a text prompt, as well as a web interface.
git clone https://github.com/lstein/stable-diffusion.git
cd stable-diffusionNext, move the model file downloaded previously, into this repo, renaming it to model.ckpt
mkdir -p models/ldm/stable-diffusion-v1/
mv ~/Downloads/sd-v1-4.ckpt models/ldm/stable-diffusion-v1/model.ckptCreate the conda environment
While still in the Stable Diffusion repo, create the conda environment in which the scripts will run.
conda env create -f environment.yamlThe first time this step runs, it will take a long time, due to the numerous dependencies involved.
Run Stable Diffusion
Once the setup is done, these are the steps to run Stable Diffusion. Activate the conda environment, preload models, and run the dream script.
conda activate ldm
python scripts/preload_models.py
python scripts/dream.pyA prompt will appear where you can enter some natural language text.
* Initialization done! Awaiting your command (-h for help, 'q' to quit)
dream>As an example, try
dream> photograph of highly detailed closeup of victoria sponge cake
Wait a few seconds, and an image gets generated in the outputs/img-sample folder.
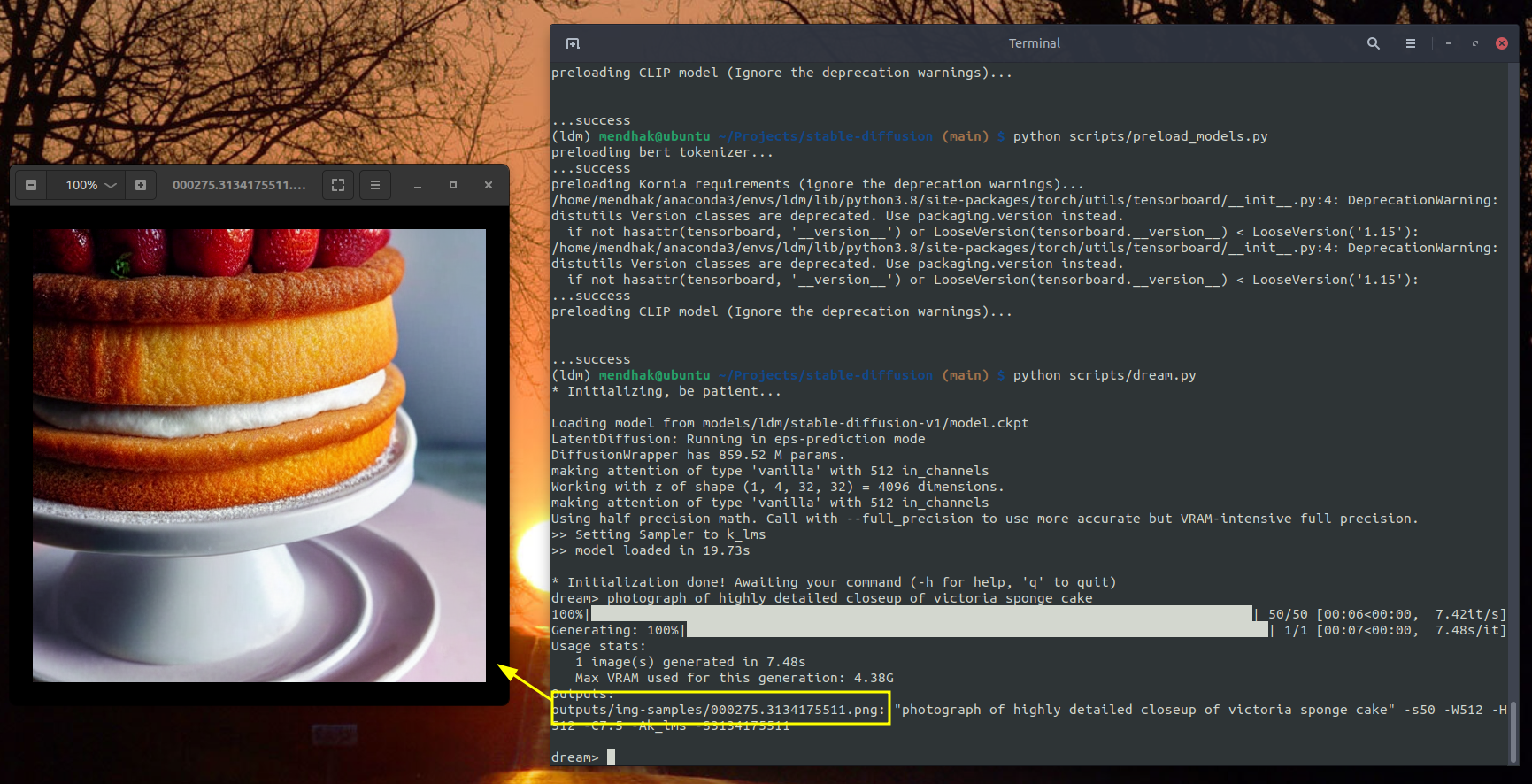
Conveniently, a dream_log.txt file shows you all the prompts you’ve run in case you want to refer back to something. Against each line, you will also see a seed number that looks something like this: -S2420237860. This allows you to regenerate the exact same image by specifying the seed with your text prompt.
dream> photograph of highly detailed closeup of victoria sponge cake -S2420237860
Using an image as a source
You can also use a crude image as a source for the prompt with the --init_img flag.
dream> mountains and river, Artstation, Golden Hour, Sunlight, detailed, elegant, ornate, rocky mountains, Illustration, by Weta Digital, Painting, Saturated, Sun rays --init_img=/home/mendhak/Desktop/rough_drawing.png
You can take the output from one step and re-feed it as the input again, and come up with some interesting results.



Generating larger images
By default the output is 512x512 pixels. There is a separate module you can use to upscale the output, called Real-ESRGAN.
It’s really simple to install, while in the conda ldm environment, run:
pip install realesrganAfter it’s installed, go back into the dream script, generate an image, and this time add the -U flag at the end of the prompt (either 2 or 4)
dream> butterfly -U 4
Face restoration
The module for face restoration is called GFPGAN. Follow its installation instructions here, clone the GFPGAN directory alongside the stable-diffusion directory. And be sure to download the pre-trained model as shown. You can then use the -G flag as shown in the Dream Script Stable Diffusion repo.
Notes and further reading
Type --help at the dream> prompt to see a list of options. You can use flags like -n5 to generate multiple images, -s for number of steps, and -g to generate a grid.
More details, including how to use an image as a starting prompt, can be found in the README.
Prompts
If you’re like me, you will need ideas for prompts. The best place to start, I’ve found, the Lexica.art site. Find something interesting, and copy the prompt used, then try modifying it.