As I spend a lot of time on the CLI, I often need to look up commands, even if I’ve used them before. I like to offload memory elsewhere if I don’t need to remember things, including commands, boilerplate code, birthdays, phone numbers and so on, and do a search when I need them. As a convenience, I have written a CLI lookup tool, accessible from the commandline itself. It works by making use of LLMs such as OpenAI GPT 3.5 and Llama2.
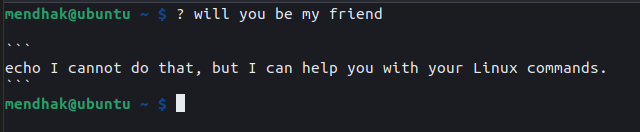
? in actionUsage
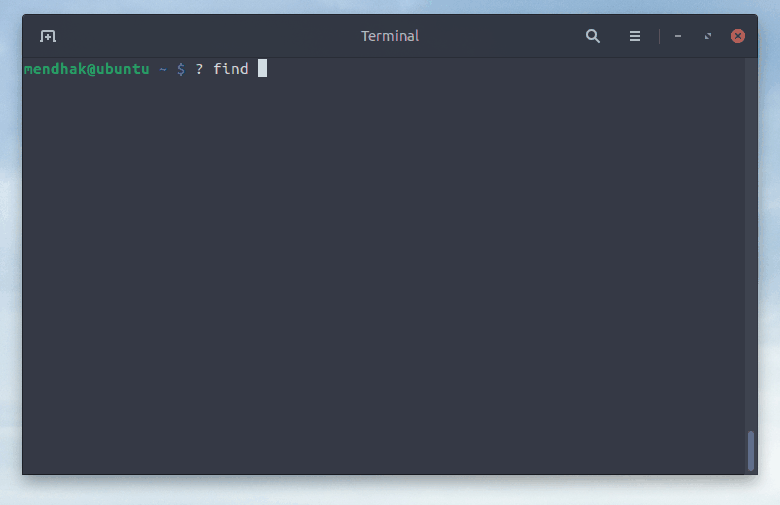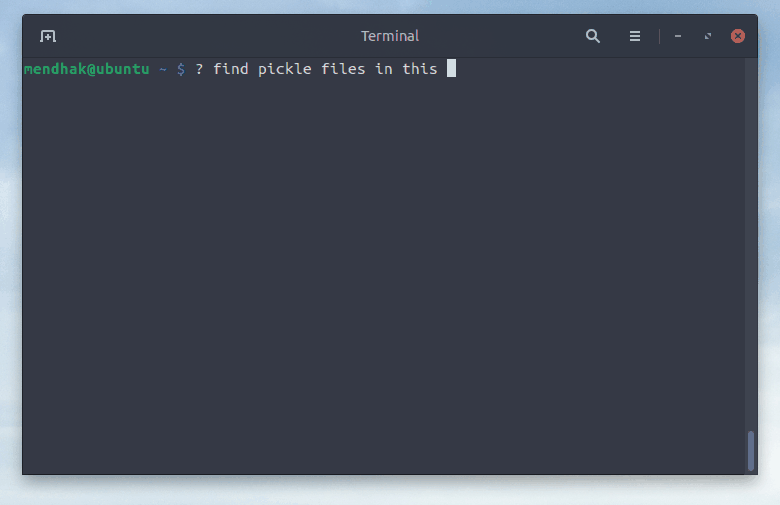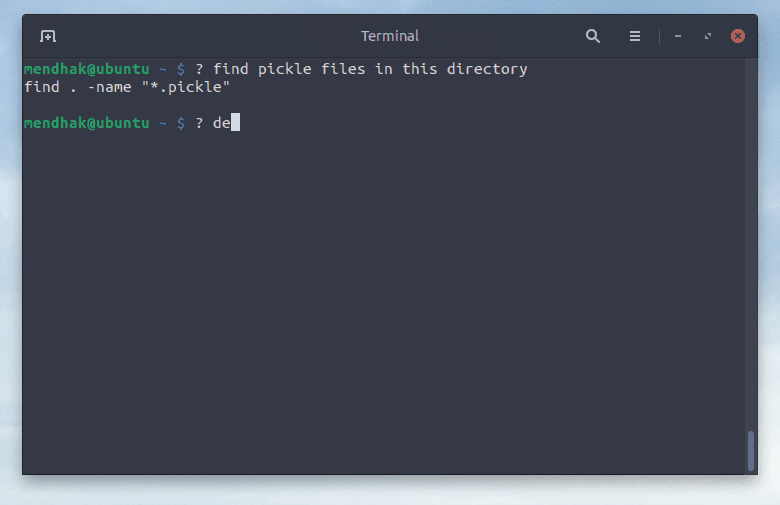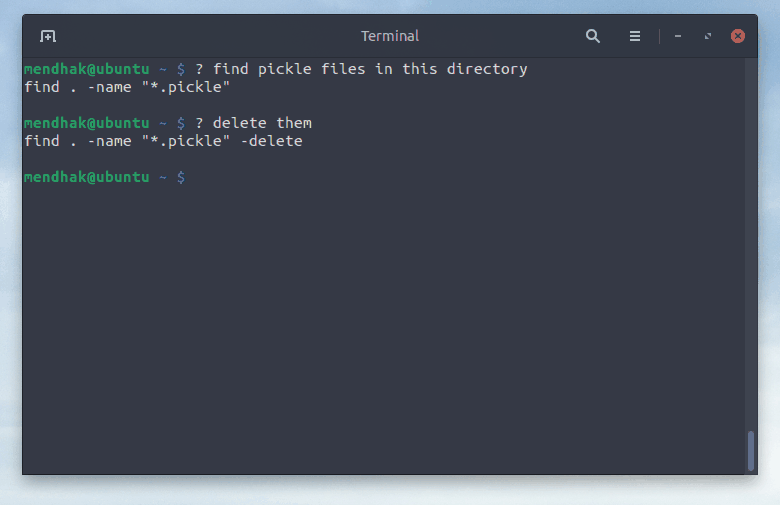
I type ? followed by a brief description of the command I’m trying to remember.
$ ? how much disk space
df -h
$ ? show top processes by CPU usage
top -o %CPUThe tool maintains a bit of history, so it’s possible to ask a follow up command.
$ ? find .pickle files in this directory
find . -type f -name "*.pickle"
$ ? delete them
find . -type f -name "*.pickle" -deleteSimilarly in this example, I didn’t like the first output using telnet, so I asked for an nc command instead.
$ ? check if port 443 on example.com is open
echo | telnet example.com 443
$ ? using nc
nc -zv example.com 443How it works
Large Language Models (LLMs) having crawled large parts of the Internet, will have a decent idea of how to formulate common commands. In effect, they can serve as a sometimes reliable search engine. Now that LLMs are becoming increasingly accessible, it is becoming easier to write tooling against these. It’s then just a matter of writing the right prompts to get the desired answer out.
The models
OpenAI’s GPT 3.5 API is a popular choice currently as it gives access to GPT 3.5, the model behind ChatGPT. This gives slightly better answers, but is not free. The pricing is cheap but it’s still a good idea to set a monthly limit on usage.
Meta’s Llama2 is more open, and can be run locally on a computer for free. Its openness has spawned a number of community efforts that run very fast on GPUs. Since this setup runs on local hardware, it’s effectively free, with the downside that its answers are not as good as GPT 3.5’s.
I’ve written the CLI helper against both of these models.
The prompts
This is where we meet the hottest new programming language, English. Programming against LLMs involves writing prompts in a specific way hoping, praying, and hand-waving that it gives you what you want.
The initial layout of the prompt looks something like this:
You are a helpful assistant that outputs example Linux commands.I will describe what I want to do, and you will reply with a Linux command to accomplish that task.
I want you to only reply with the Linux Bash command, and nothing else.
Do not write explanations. Only output the command.
If you don't have a Linux command to respond with, say you don't know, in an echo command.
Human: List files in the current directory
Assistant: ls
Human: Push my git branch up
Assistant: git push origin <branch>
Human: What is a pineapple?
Assistant: Sorry, I don't have a bash command to answer that.
The initial paragraph sets the role, and the examples given help the LLM understand the kind of responses being expected. This is known as few shot prompting.
Although it’s possible to just send this block of text to the APIs directly and parse the response, I’m using an emerging framework called LangChain, which simplifies and takes away some of the setup and boilerplate involved. This includes setting up the initial context, the examples, maintaining a history, and processing the output.
? is just an alias
The scripts are in Python but it’s simpler to just alias ? to it.
alias ?='/home/mendhak/Projects/llm-cli-helper/.venv/bin/python3 /home/mendhak/Projects/llm-cli-helper/llamacpp.clihelper.py'Using ? makes it easy to remember, and makes the interface appear like a proper search. Simple. It creates no illusions of talking to an entity with agency.
A detailed look at the models
The well known proprietary models such as ChatGPT and Claude 2 are held in closed systems and access is through payments. Their access is straightforward, through their corresponding APIs.
llama.cpp and AutoGPTQ
With Llama and its derivatives, the situation is a bit busier. It’s technically possible to use the original Llama model released by Meta directly, however running it on consumer grade hardware is resource hungry and slow. There have been community efforts to port and speed up these models and reduce the resources they require to run.
A well-known port is llama.cpp, which aims to bring LLMs to more devices. Llama.cpp can take advantage of CPUs and GPUs. Although the CPU boost was better than running Llama2 directly, it was much faster on a GPU. On my 5 year old GPU, I was able to get around 90 tokens per second. In fact, I was even able to get it working on my phone.
A similar port is AutoGPTQ which works only on GPUs. However, running it is pretty painful because, through a series of dependencies, it requires me to be running an older version of my graphics drivers. To be more specific, it makes use of a library called PyTorch, and PyTorch, at this time, only works with CUDA Toolkit 11. Installing CUDA 11 required me to downgrade my graphics driver, which was a step too far. I’d eventually like to be able to try AutoGPTQ.
It’s worth noting that the efficiency gains come at the expense of quality and accuracy. The models need to be converted through a process known as quantization. My assumption is that for a focused tool like this one, an occasional poor answer is acceptable as long as it’s relatively quick. But then, even the biggest models can still give the occasional lemon.
Chosen models
The models I chose to run the tool with were Llama-2-7B-Chat-GGML, Stable Beluga 7B GGML, and CodeLlama 7B GGUF. The 7B indicates 7 billion parameters, which would fit in about 6GB of RAM, or 6GB of VRAM if offloaded to the GPU. GGML is the name of the quantization format that llama.cpp expects to work with, although very recently this has now changed to GGUF format.
The best model would probably have been WizardCoder 15B which is fine tuned for coding tasks, but it was in GPTQ format and probably required more VRAM than I have available. Perhaps a few years from now it becomes a bit more achievable. Another coding model called Starcoder was in GGML format but not compatible with llama.cpp.
Performance
I wanted to get an objective view of the performance and accuracy of the various models, local and remote. It was pretty easy to notice when I got wrong answers but was the model serving its purpose well?
To determine that I created an unscientific test. I came up with a list of about 60 commands, and for each one I’d make the call and time it. I recorded the time along with whether the response given was good enough; it didn’t have to be a perfectly accurate answer, just enough to nudge me in the right direction.
| Model name | Good enough answers | Average time taken |
|---|---|---|
| Stable Beluga | 73% | 2.93 s |
| Llama 2 | 60% | 2.94 s |
| OpenAI GPT 3.5 | 88% | 2.11 s |
| CodeLlama | 75% | 3.16 s |
This was expected of course GPT 3.5 runs on a high end cluster somewhere in OpenAI’s estate, while the other two were running on my computer and were the smallest possible. Considering that, Stable Beluga’s and CodeLlama’s performance was impressive despite being relatively hobbled.
I did very briefly try out the larger 13B models of Stable Beluga and Llama 2; their answers were indeed better, but the performance not as much; it was taking about 5 seconds to get a response which was just past the threshold of tolerance for me. Perhaps something to try again in the future when I have better hardware.
Conclusions
I prefer OpenAI’s quality of answers, they’ve put in a lot of resources towards training this model and it shows. At the same time, I really like the idea of a private, local LLM that I can control. I think if it’s local I might have more tolerance for the occasional poor answer.
I plan on continuing to run the Stable Beluga version and OpenAI version alternatingly, and keep a running tally in the sheet over time as I try out new and interesting commands. I might even consider randomizing which model gets loaded so that it’s an almost blind experiment.

? in action